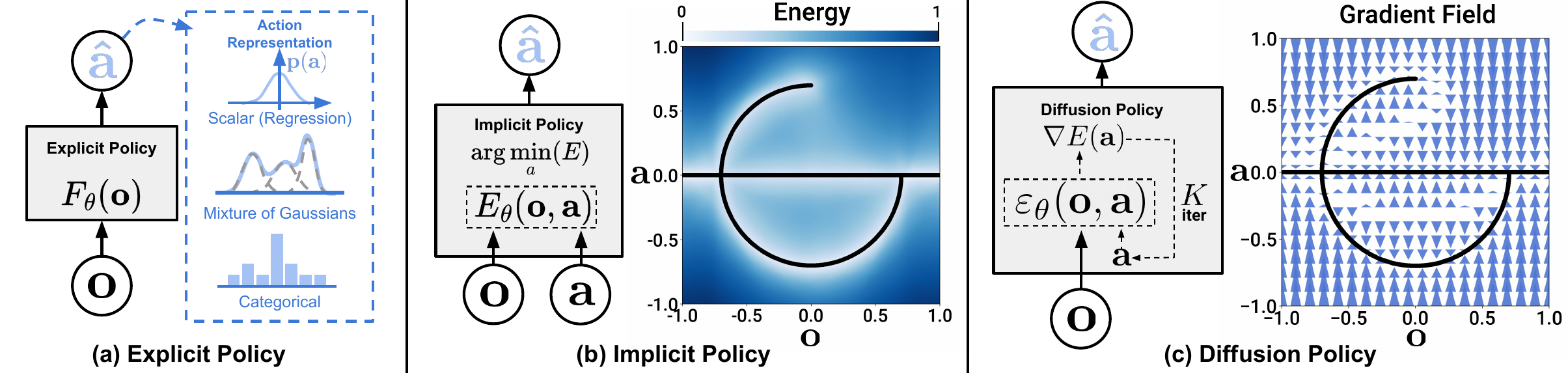
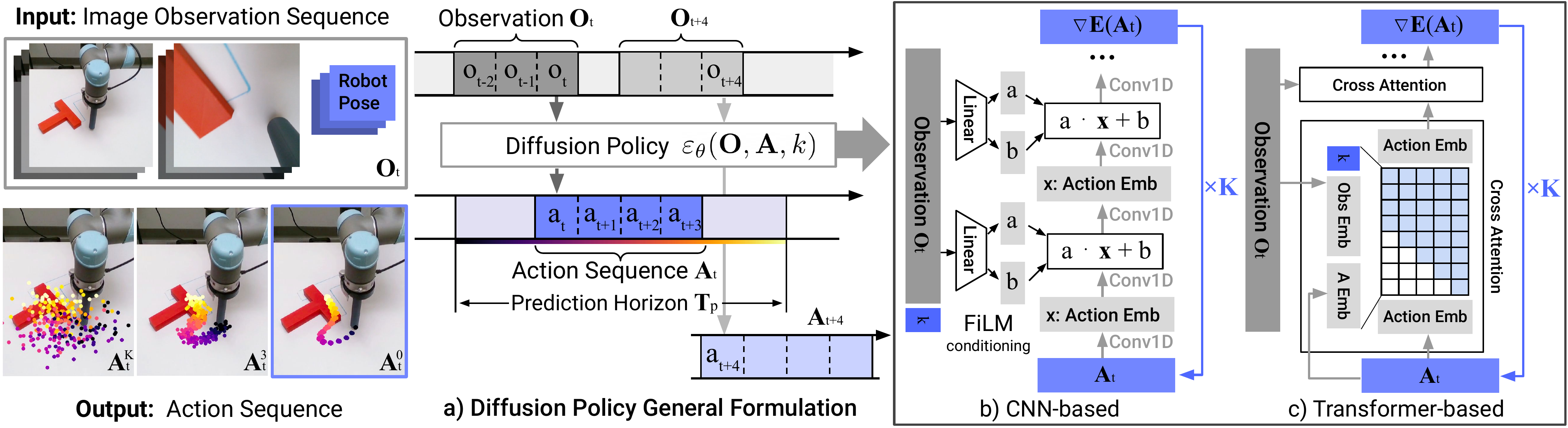
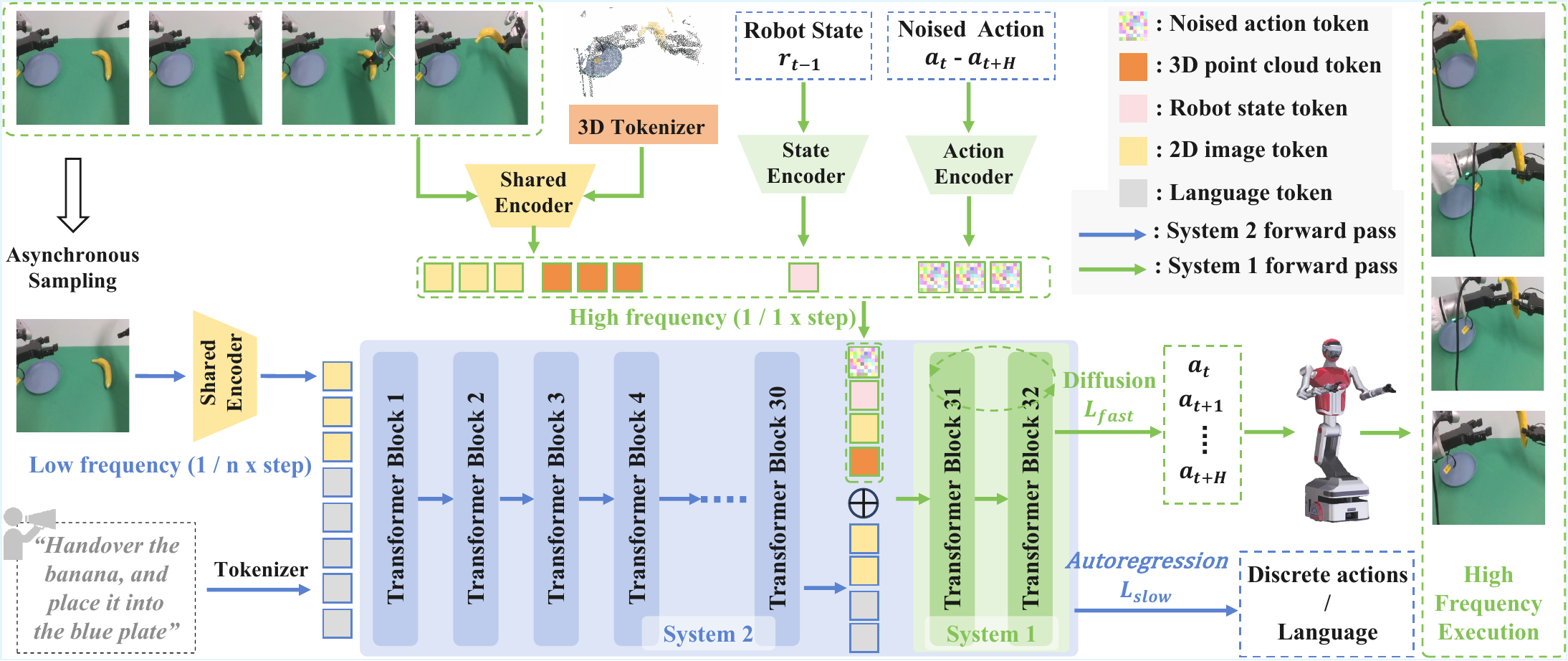
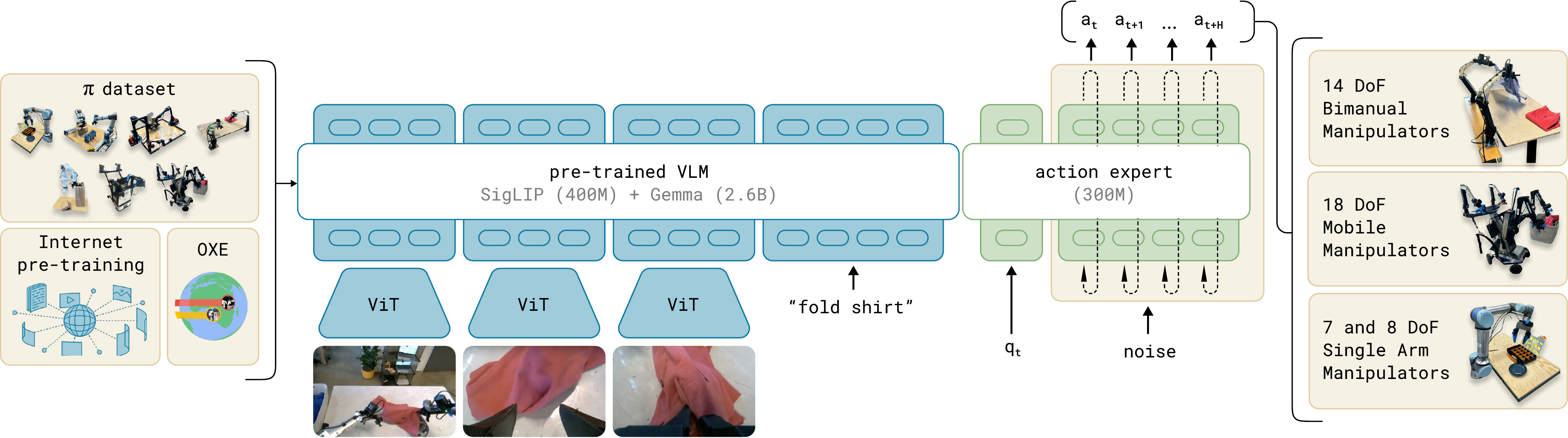
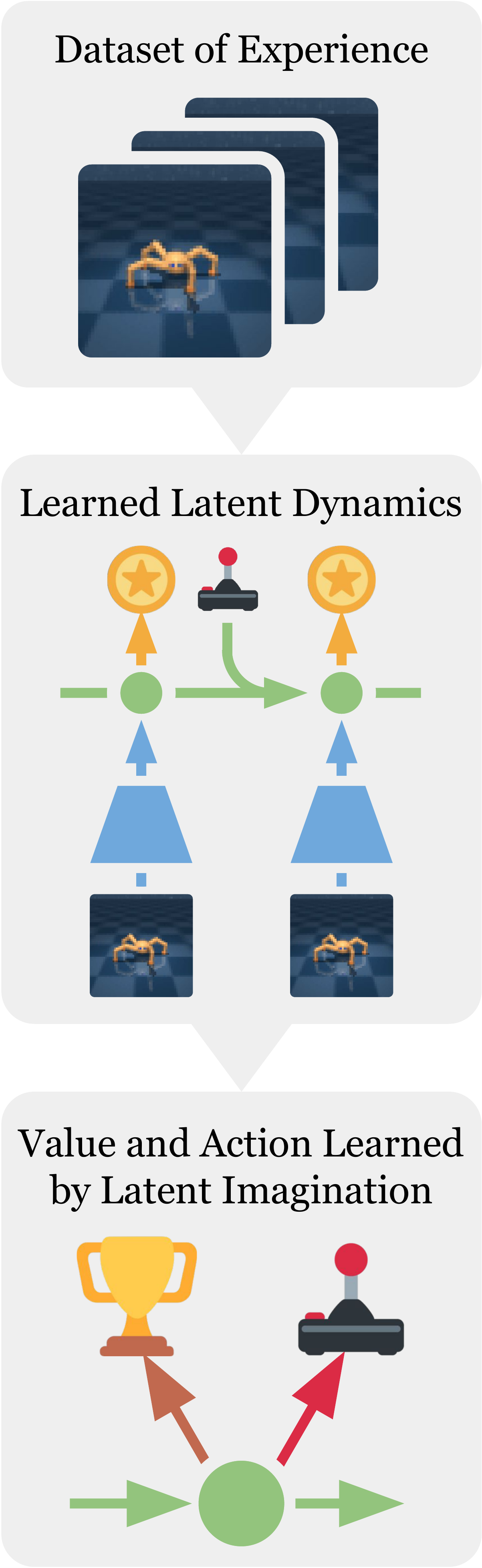
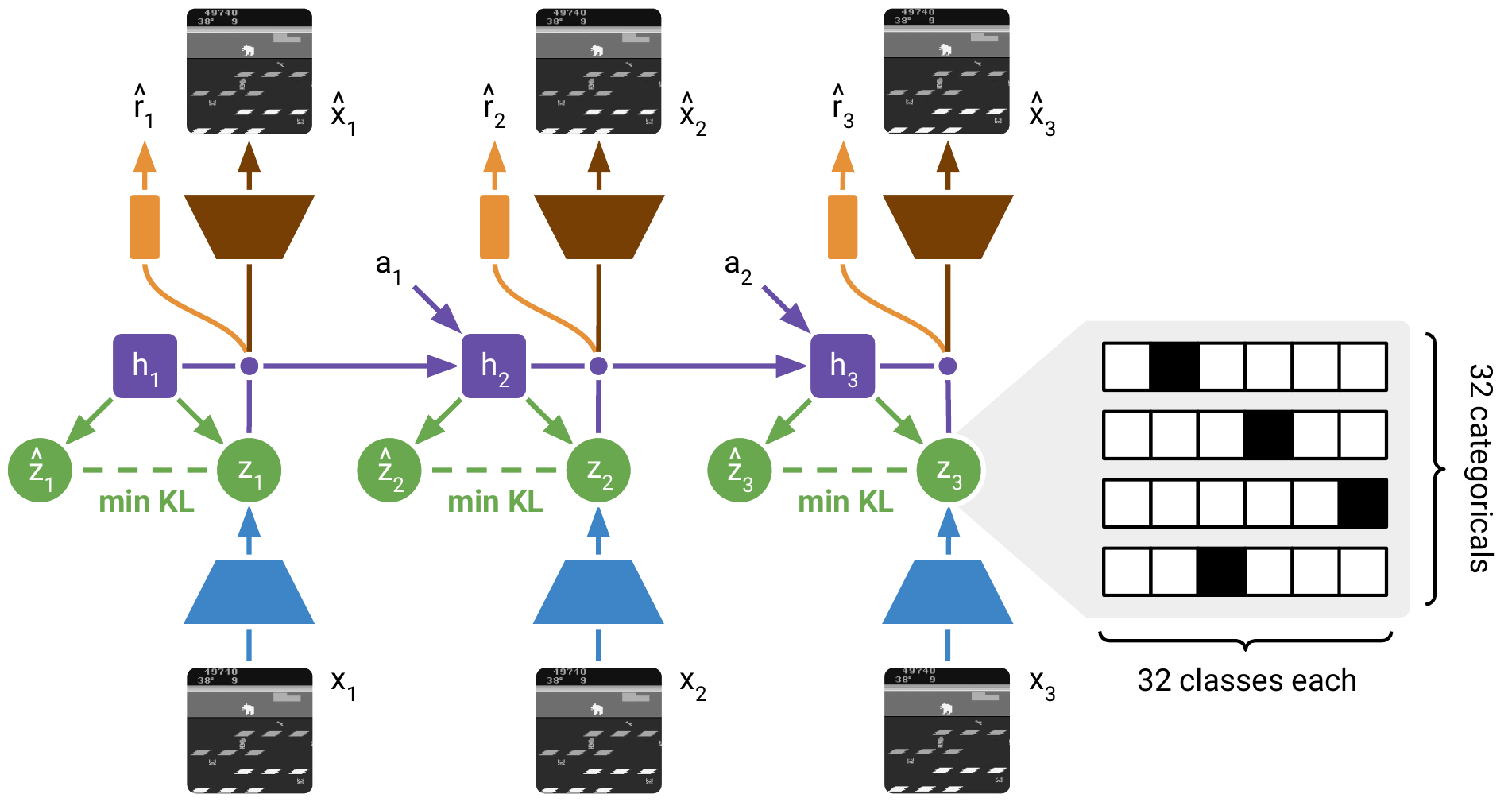
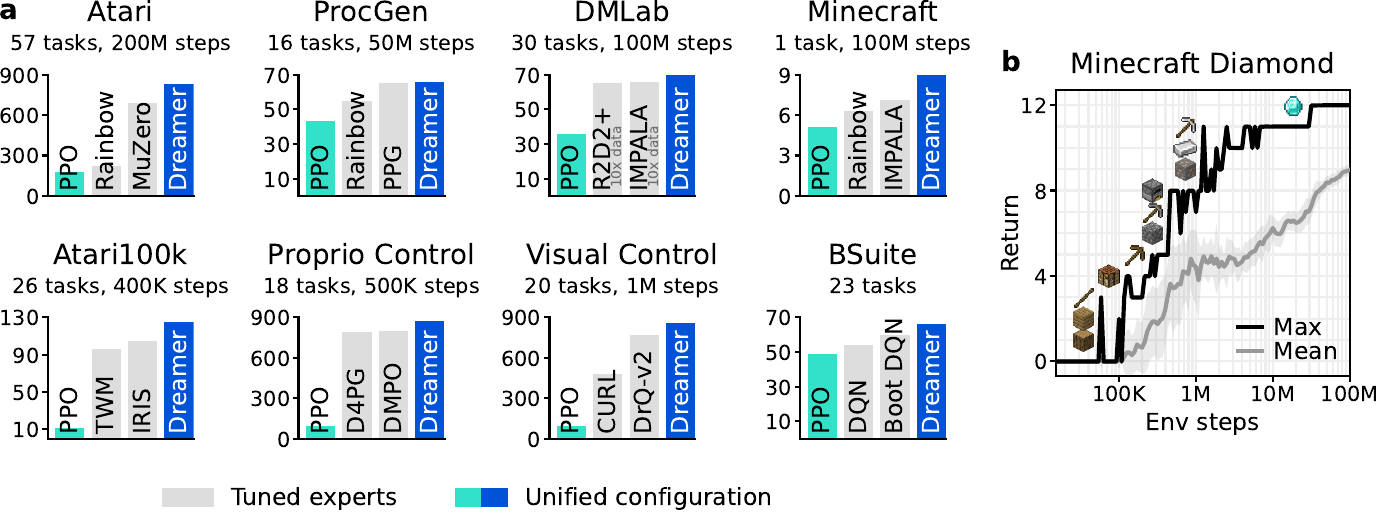
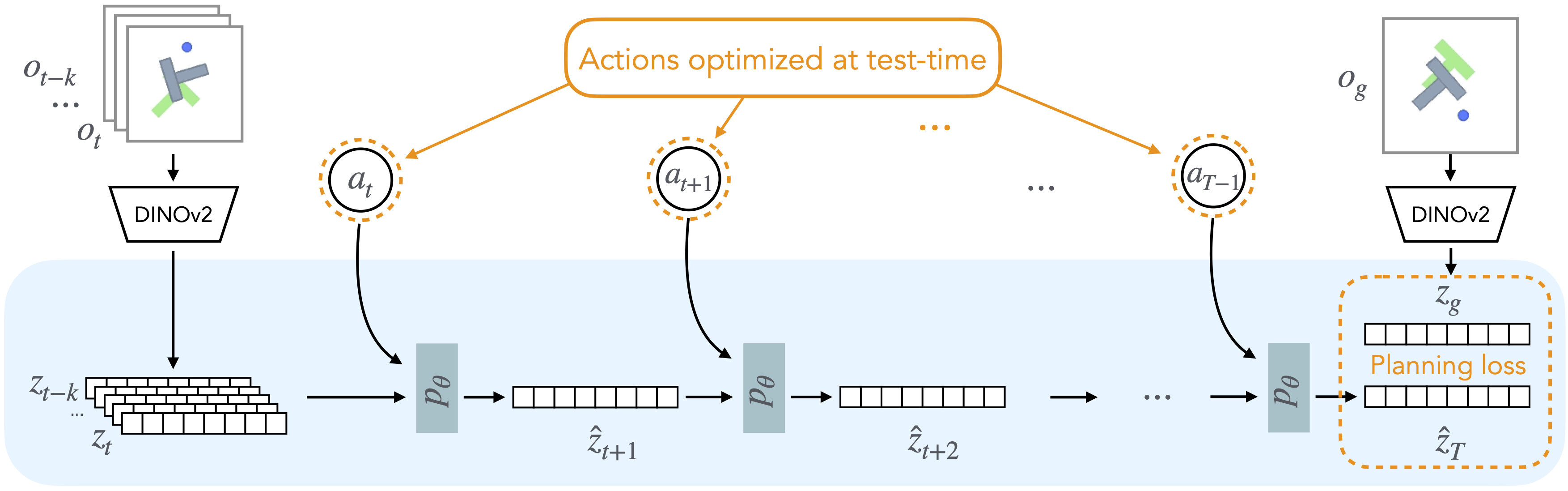
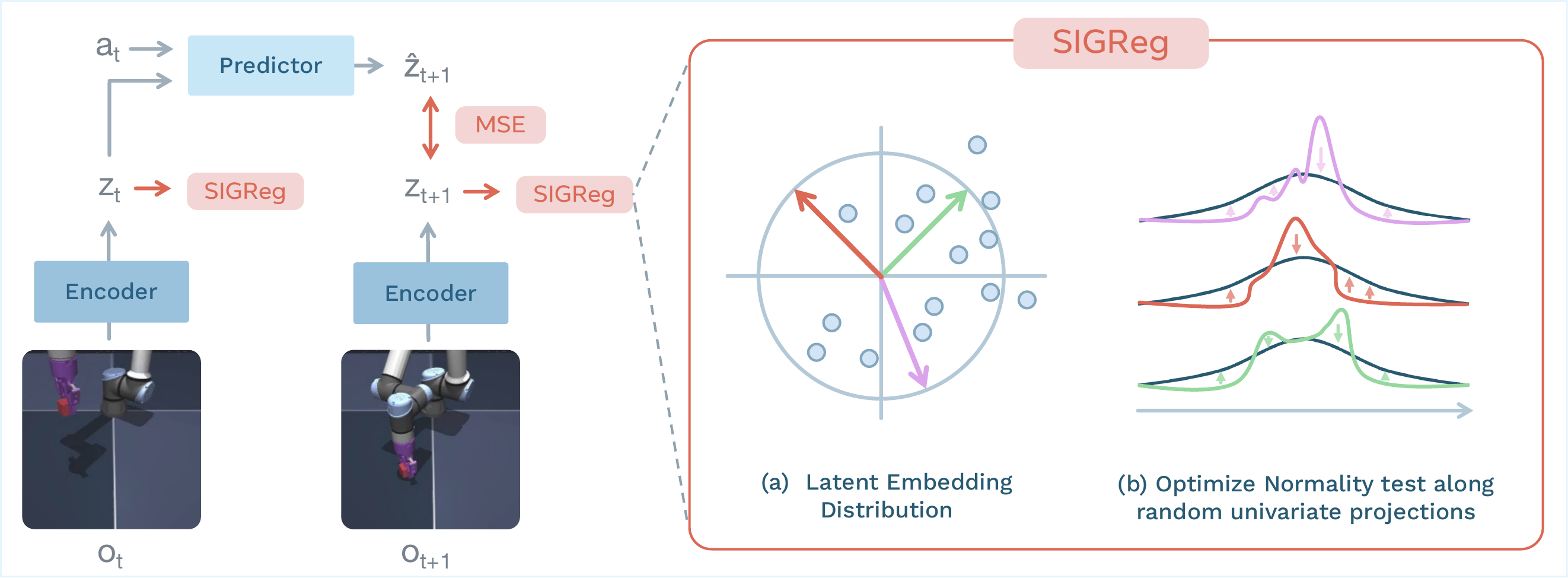
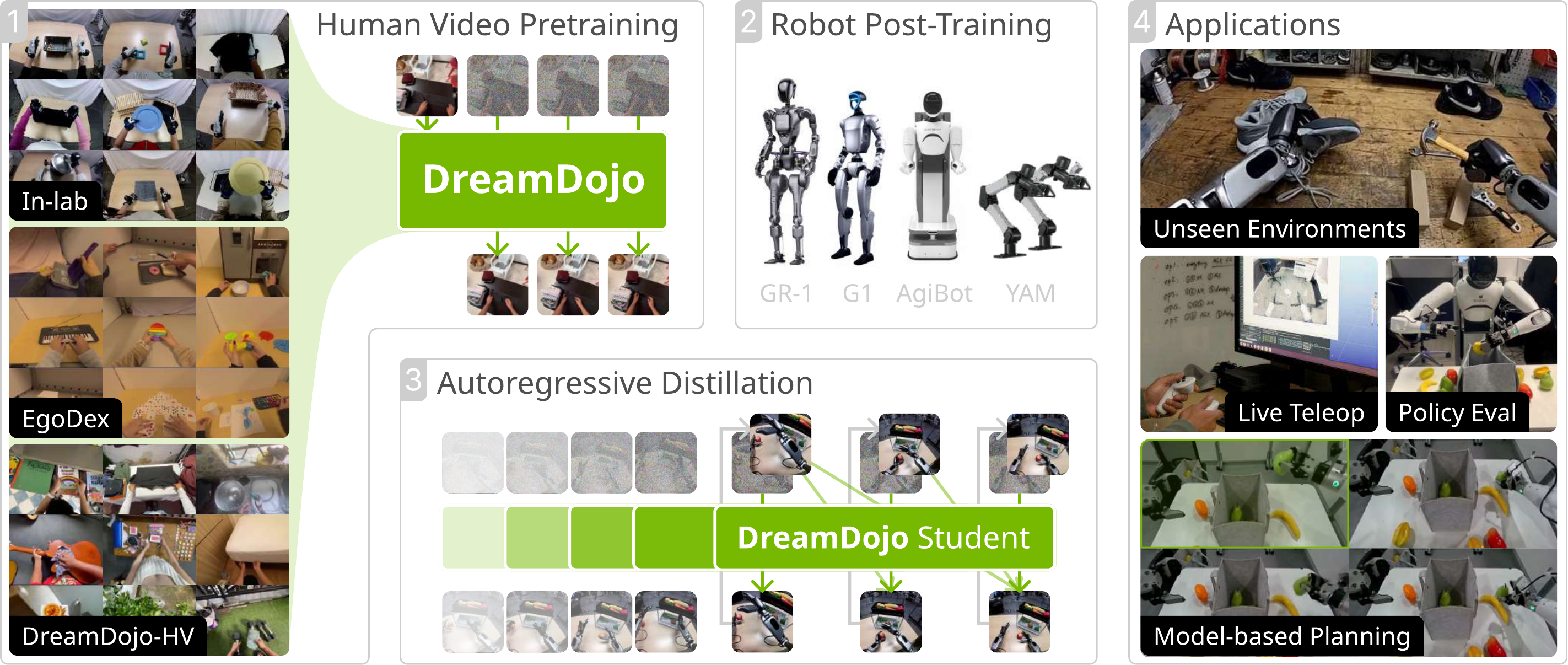
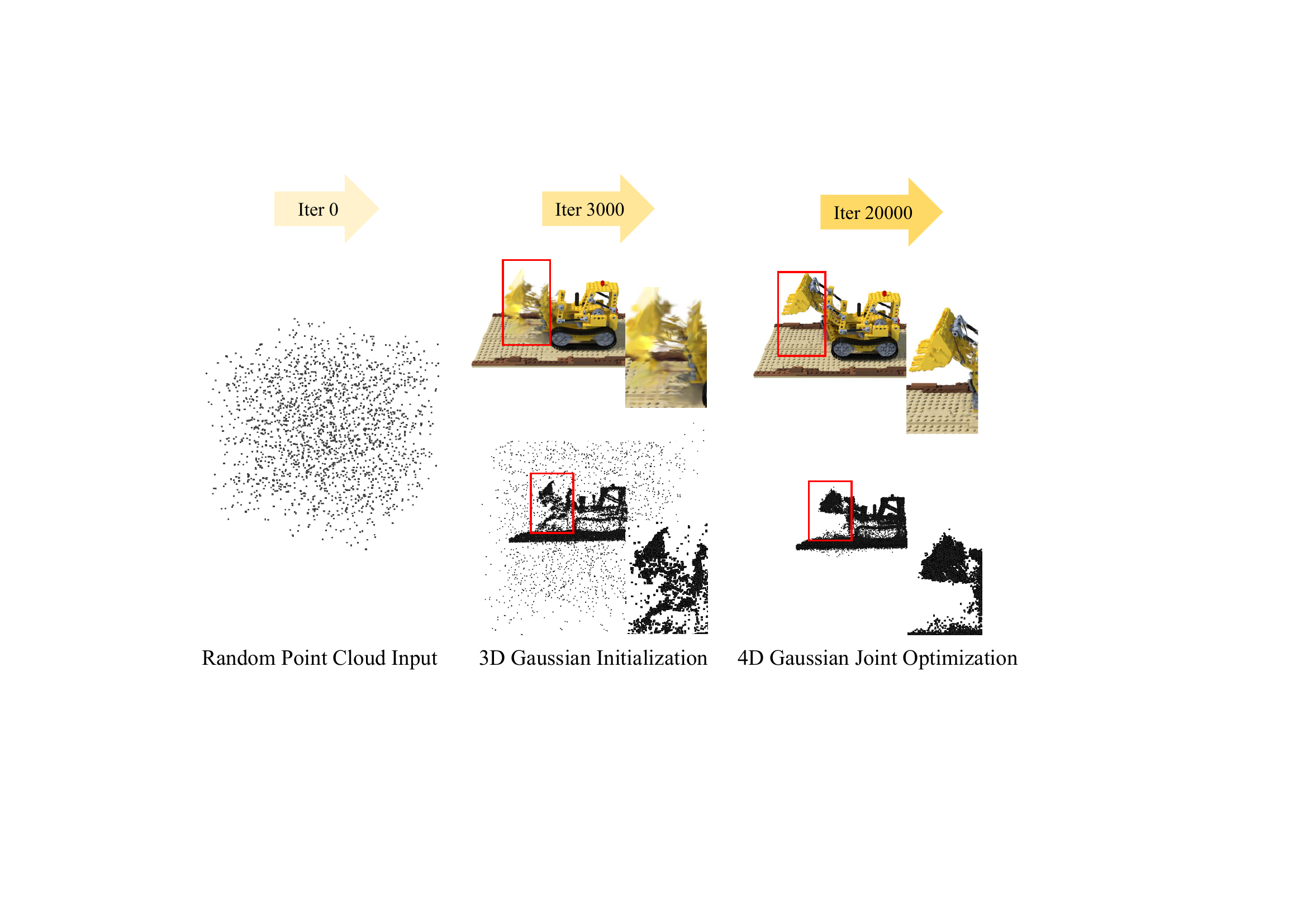
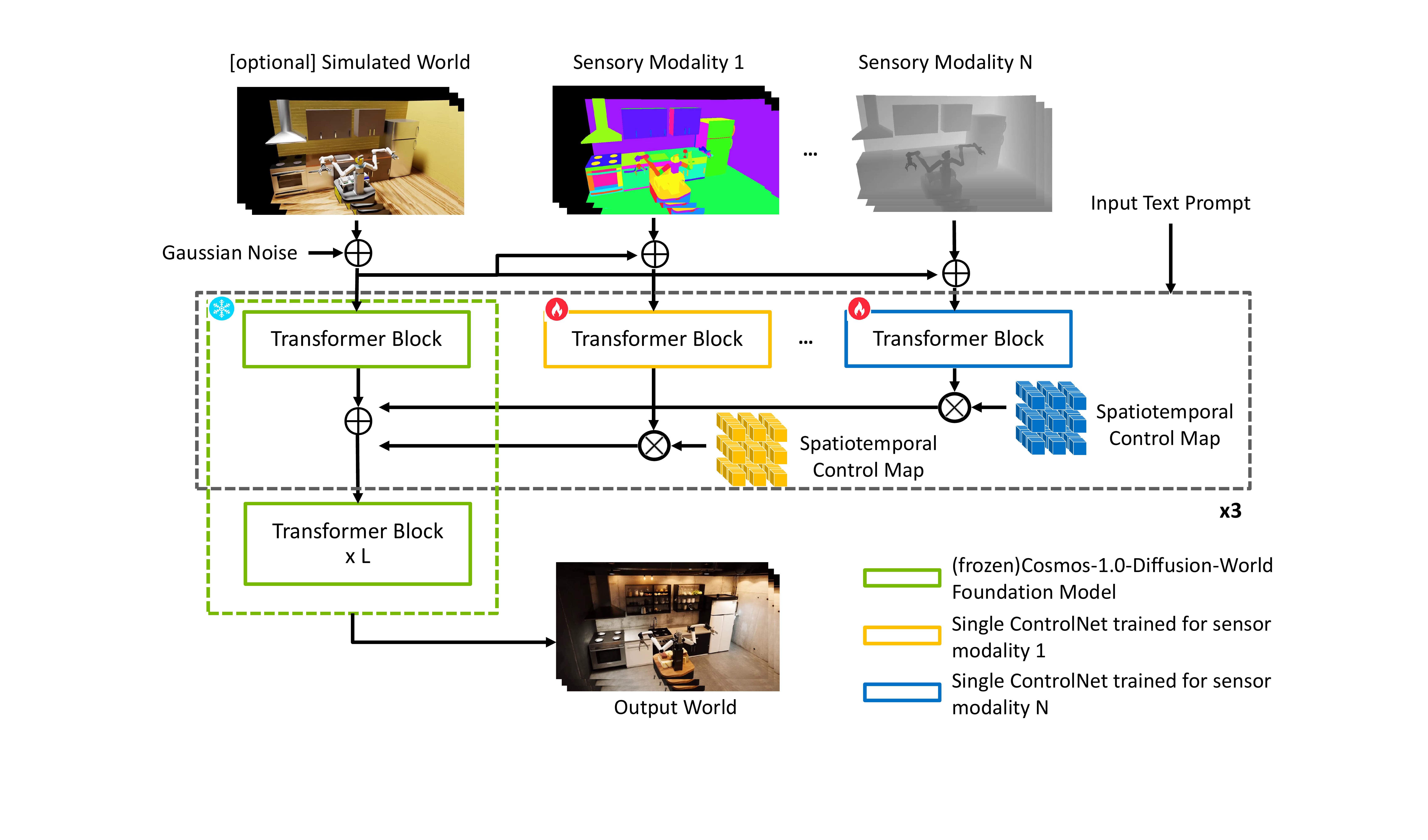
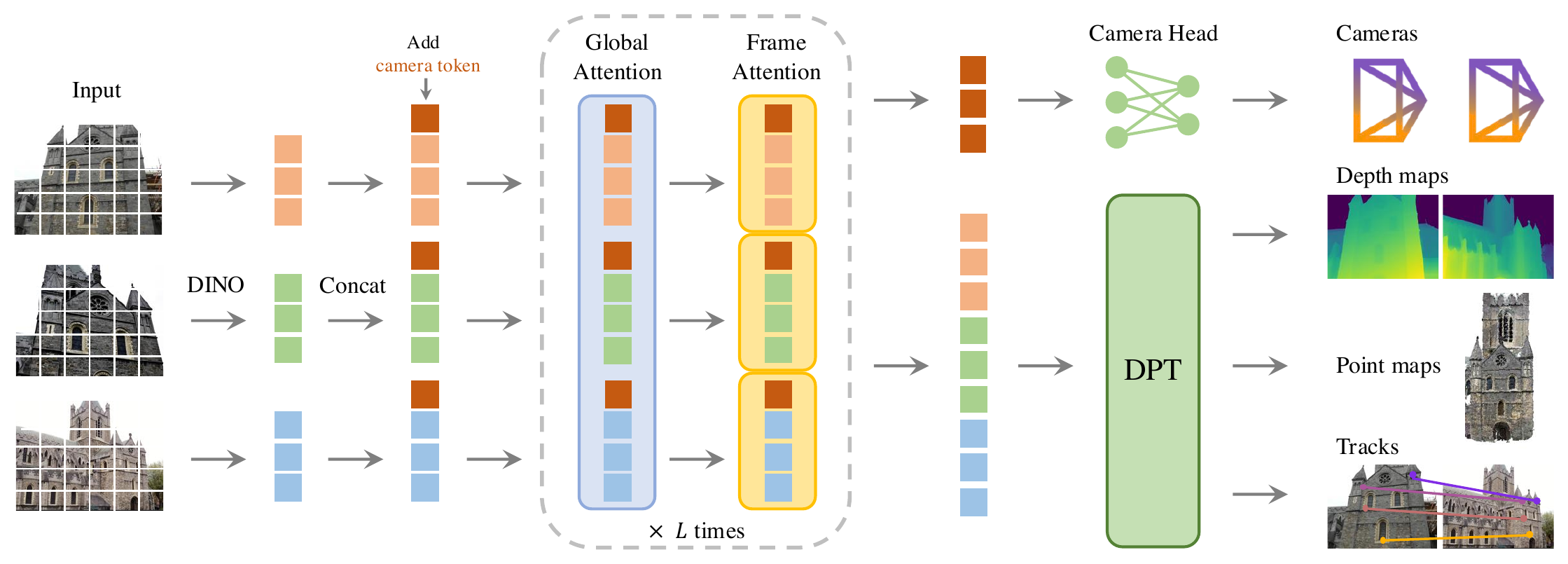
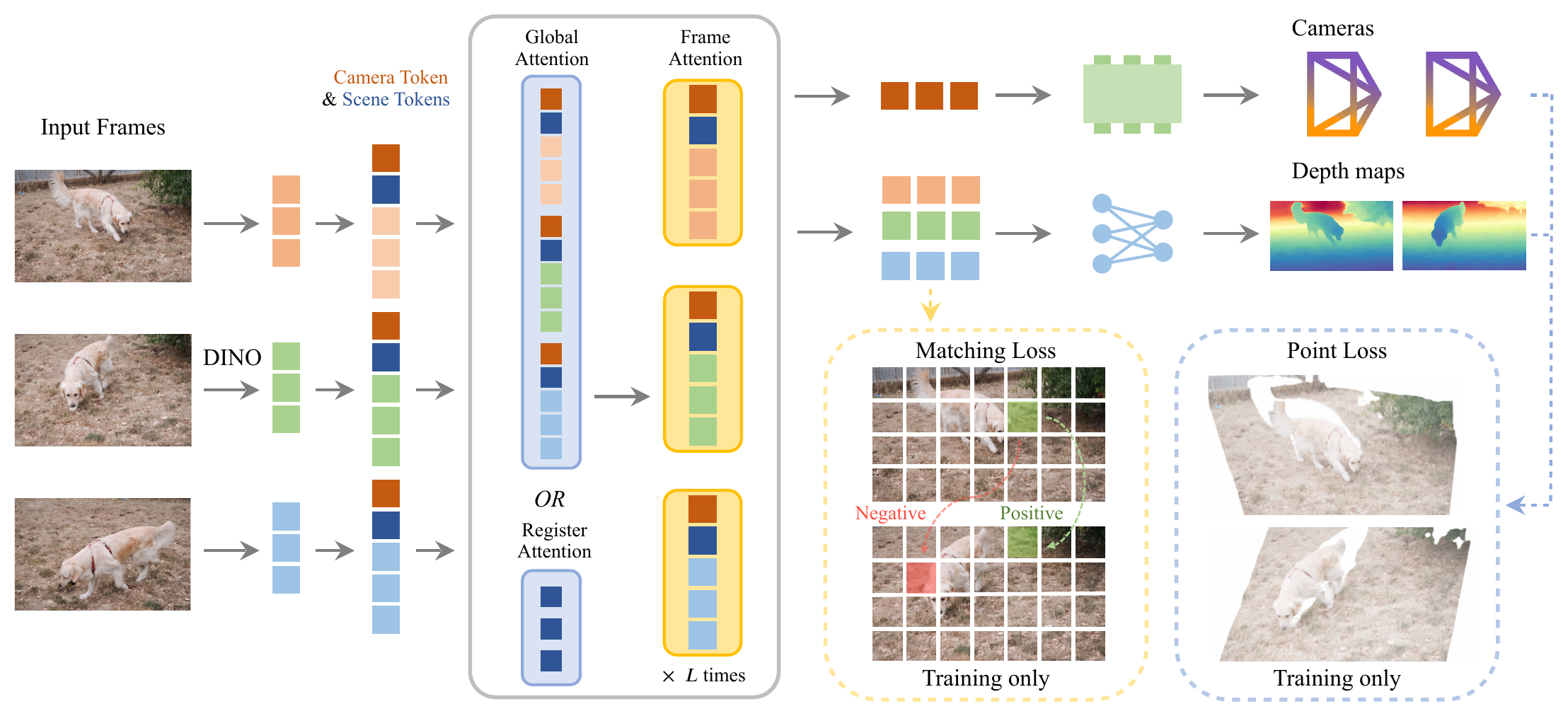
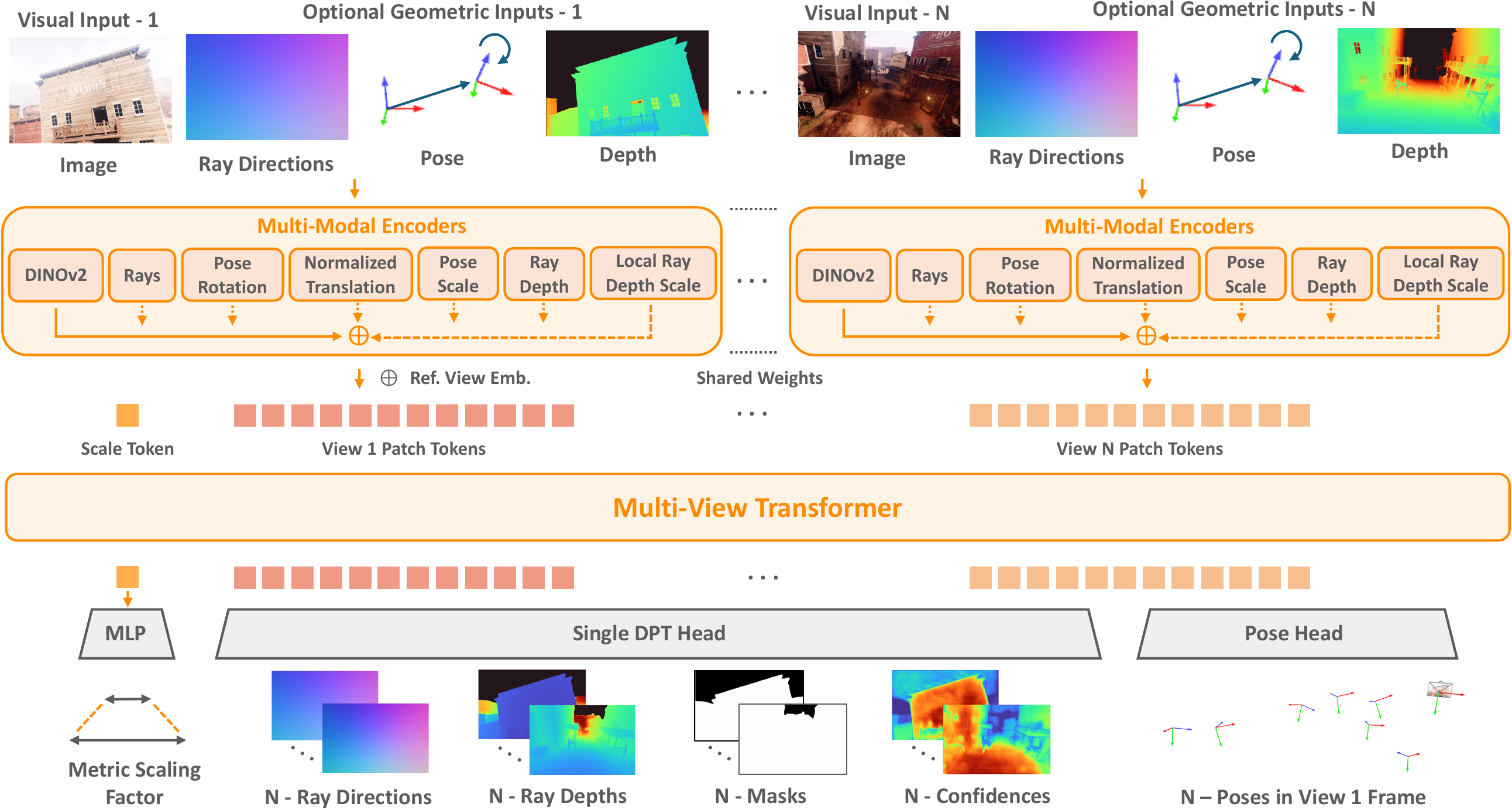
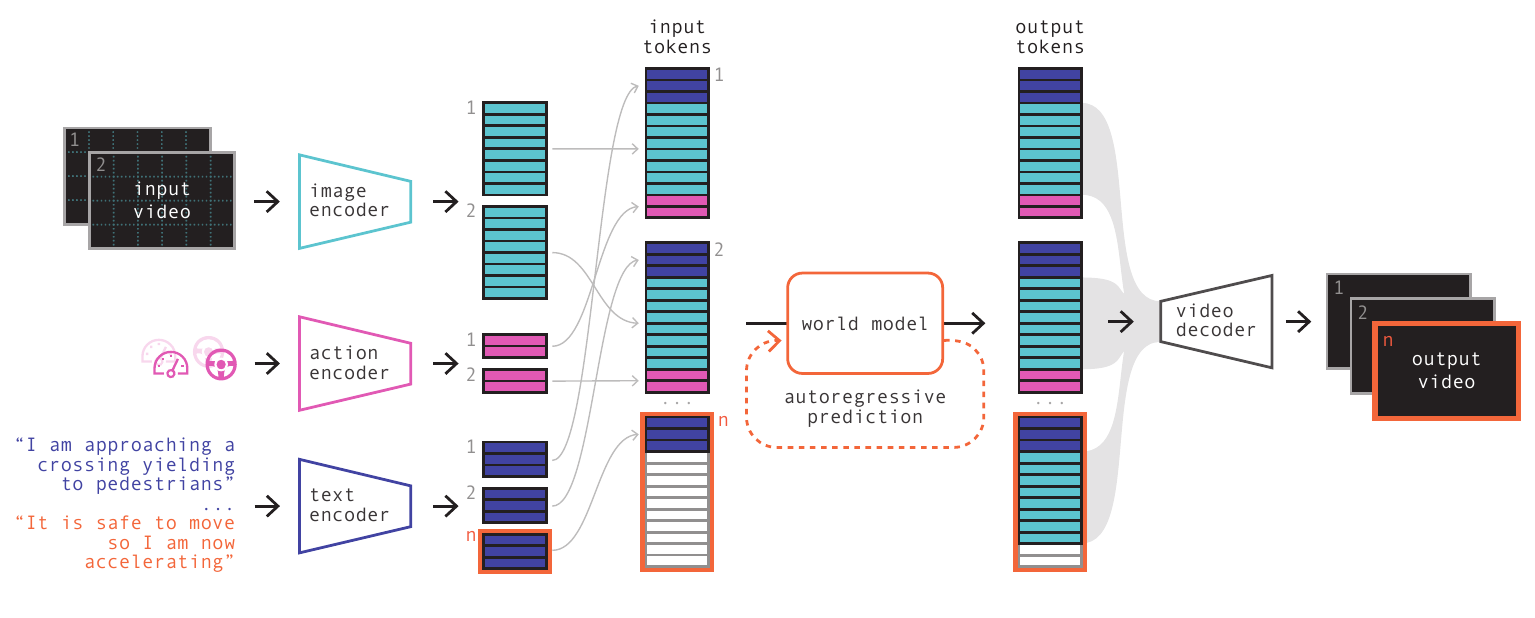
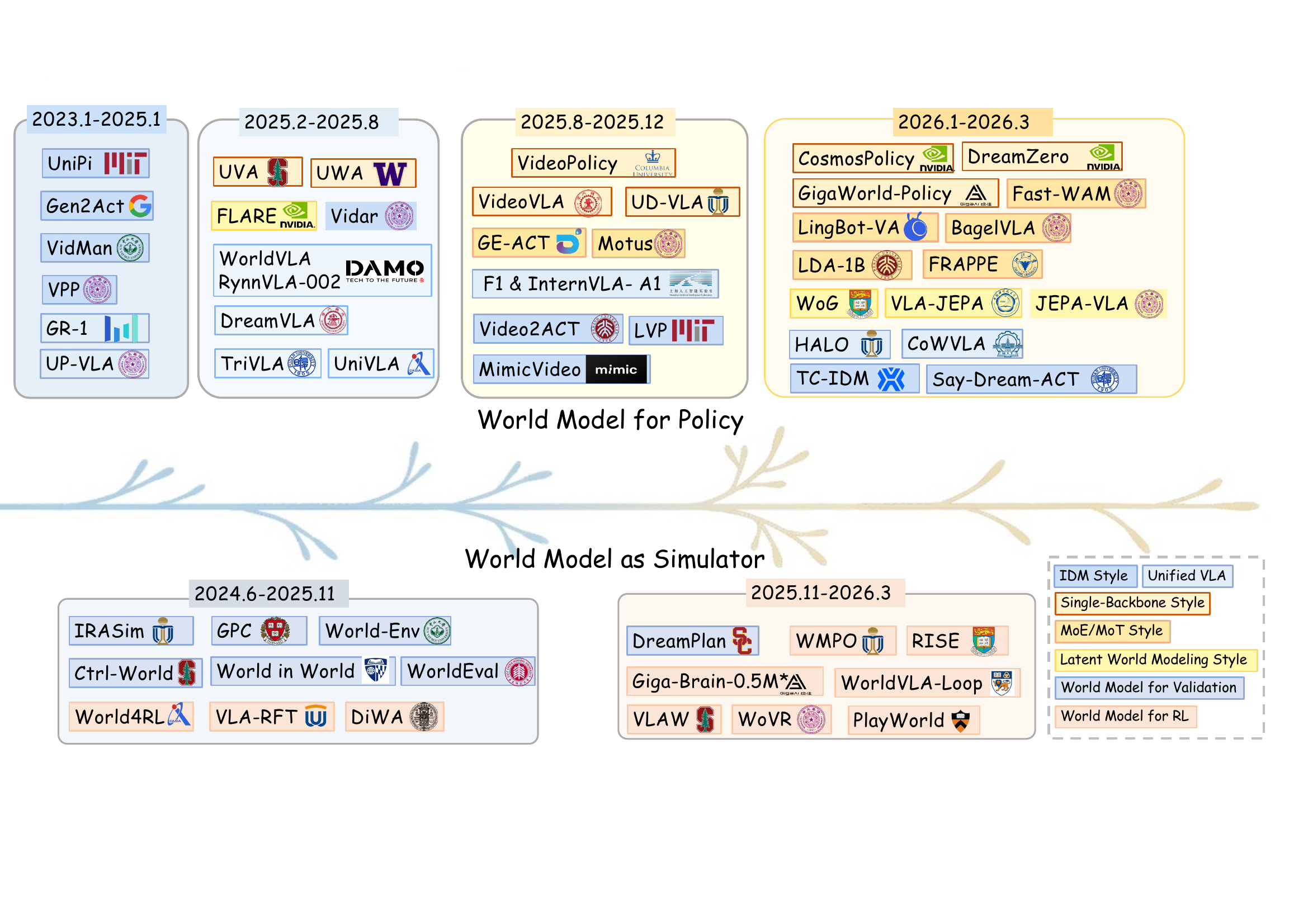
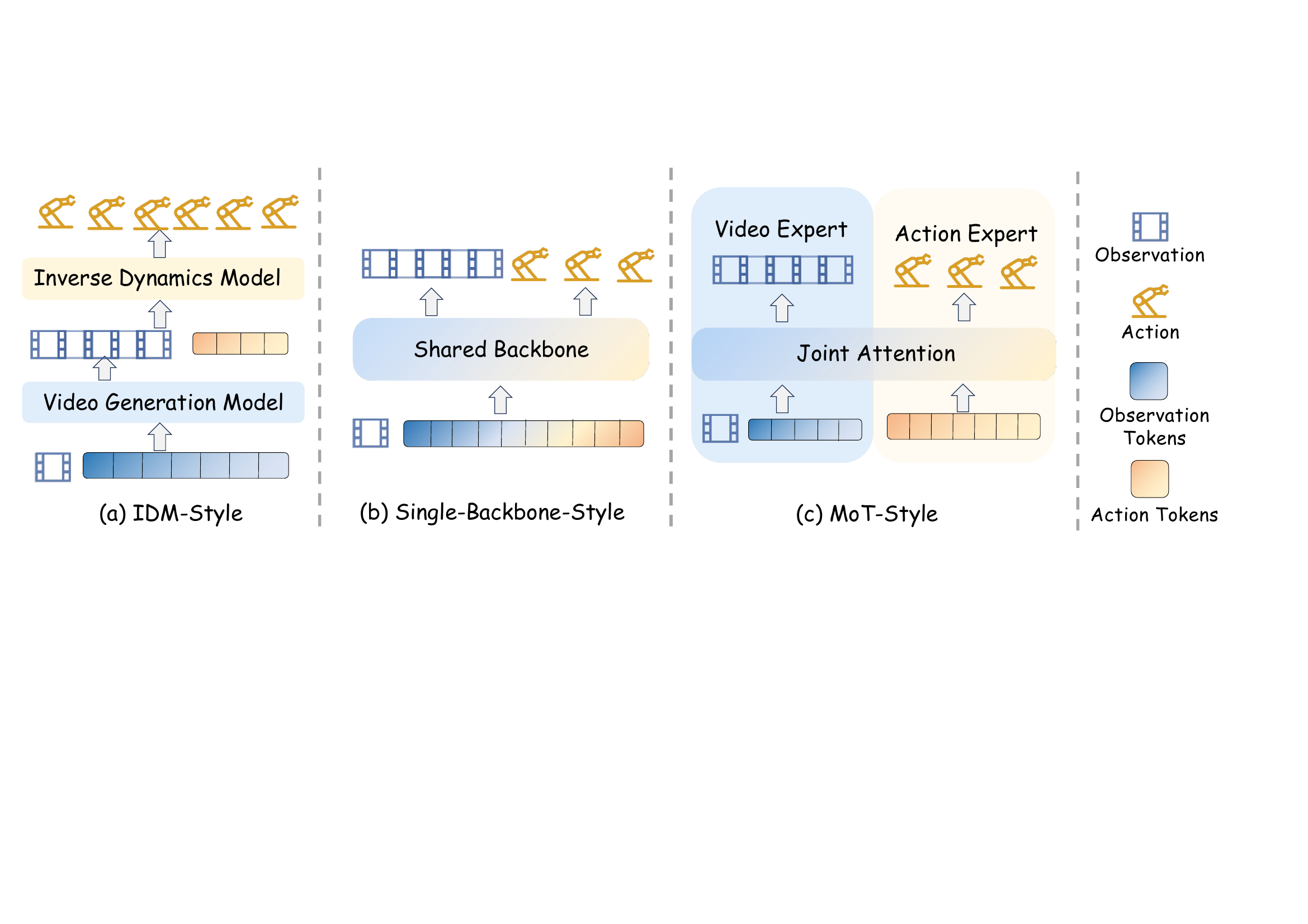
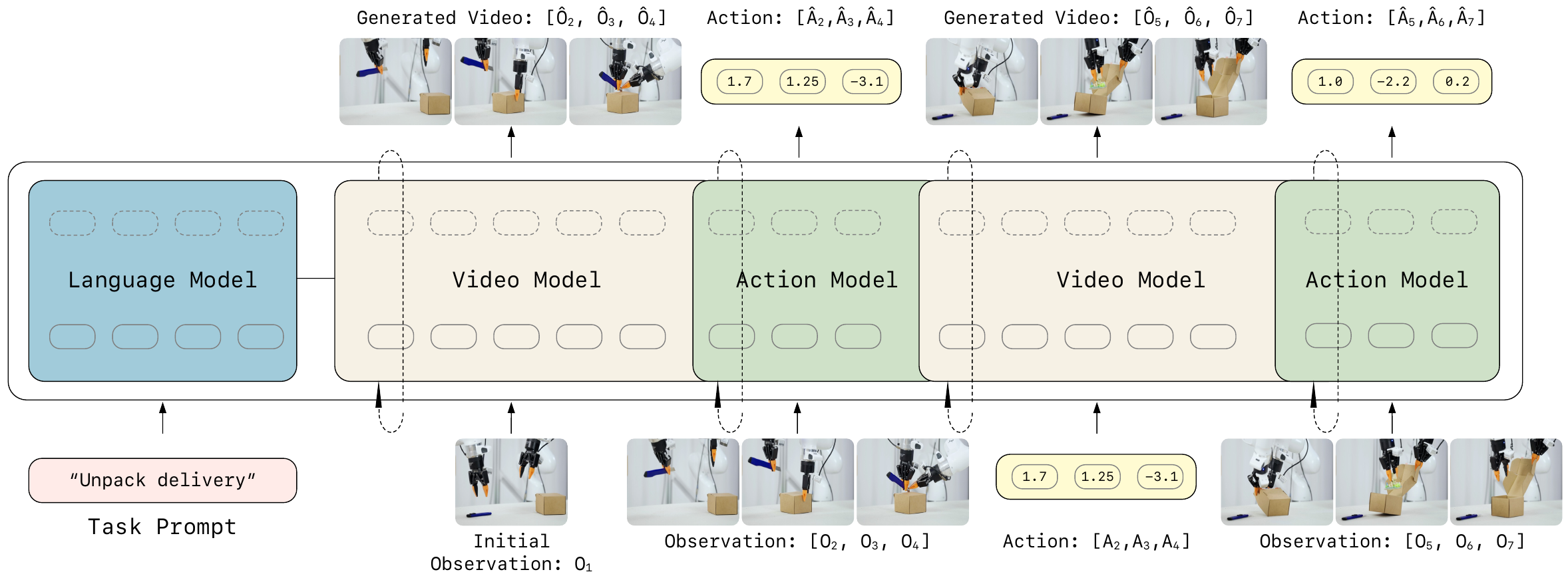
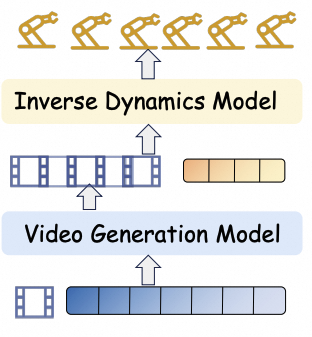
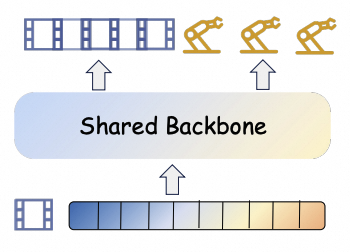
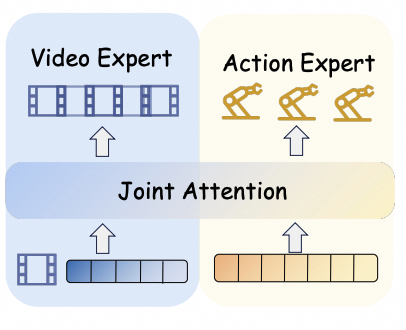
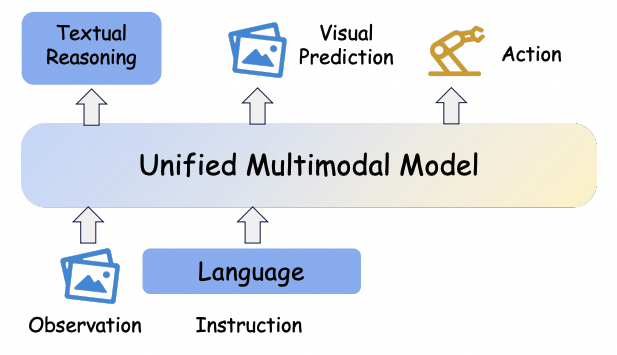
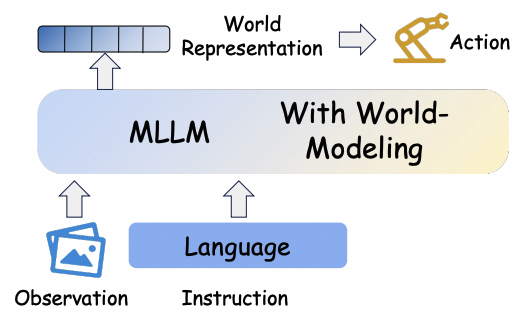
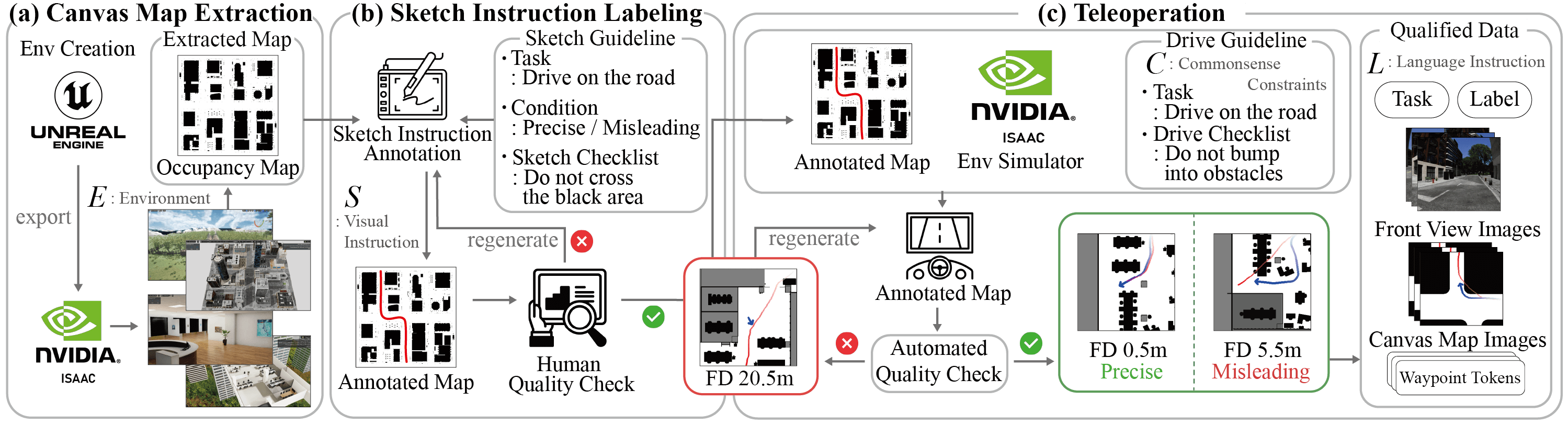
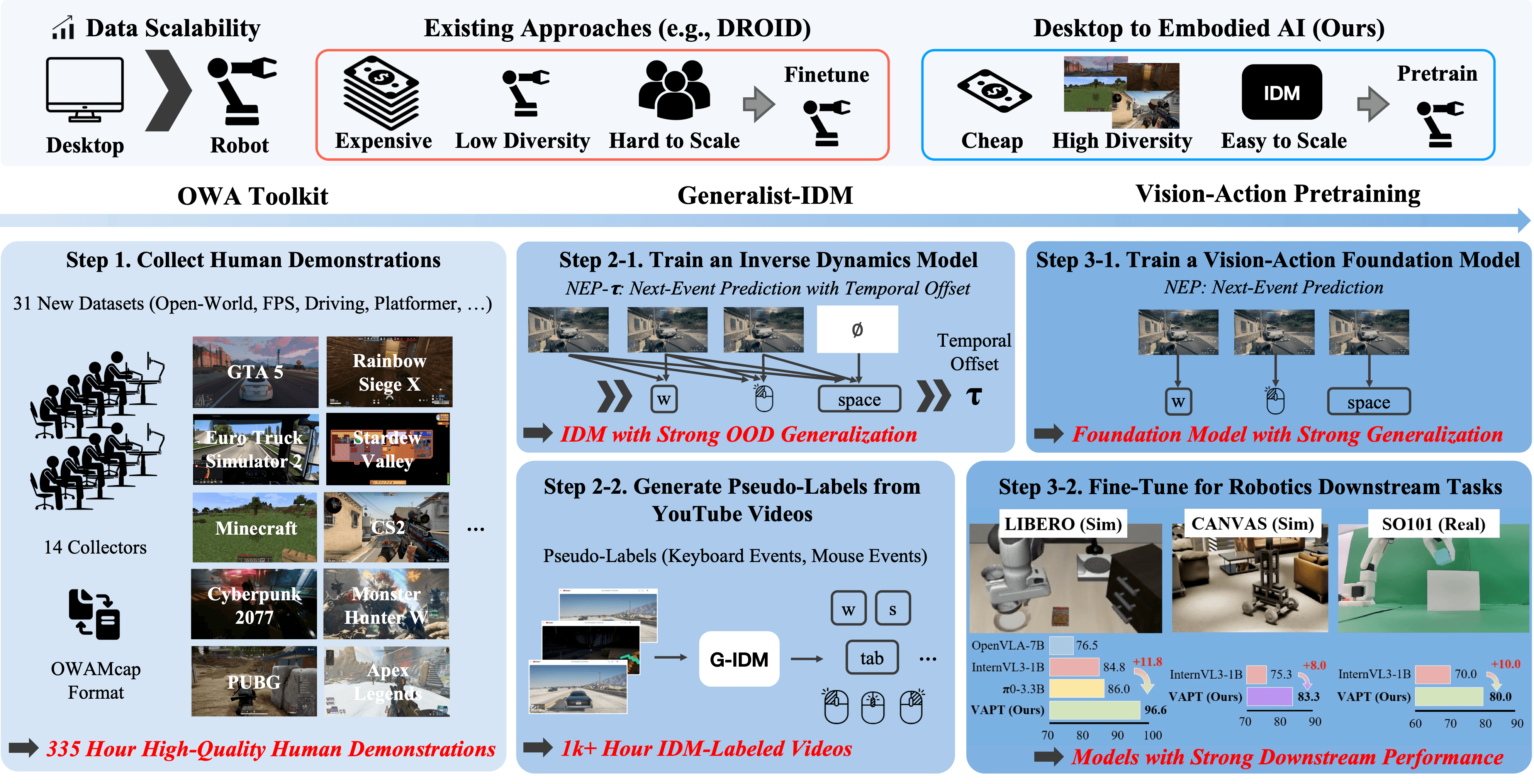
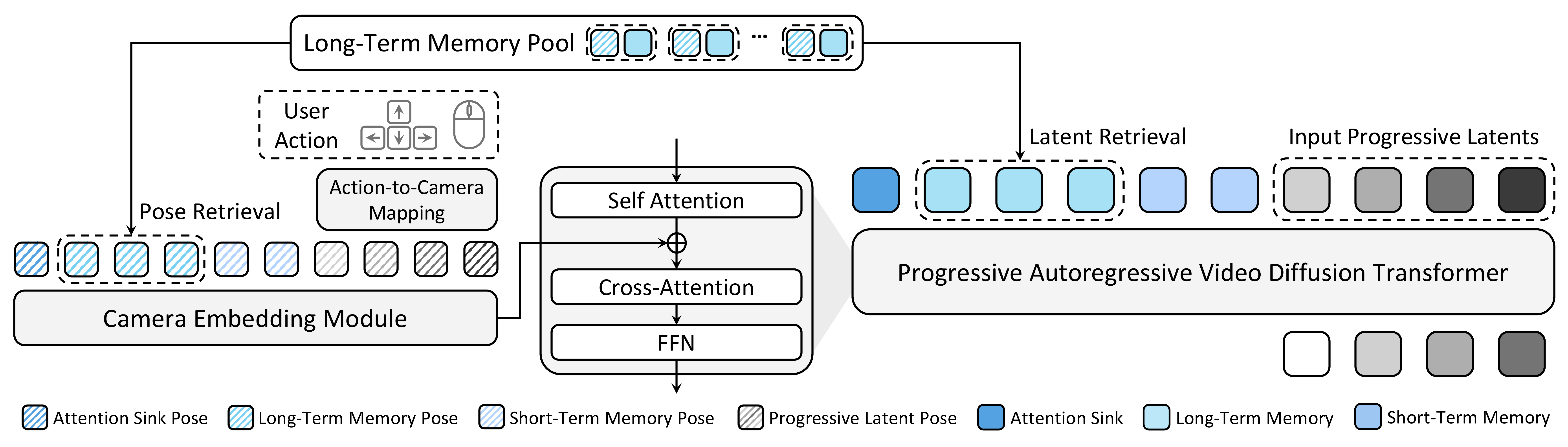
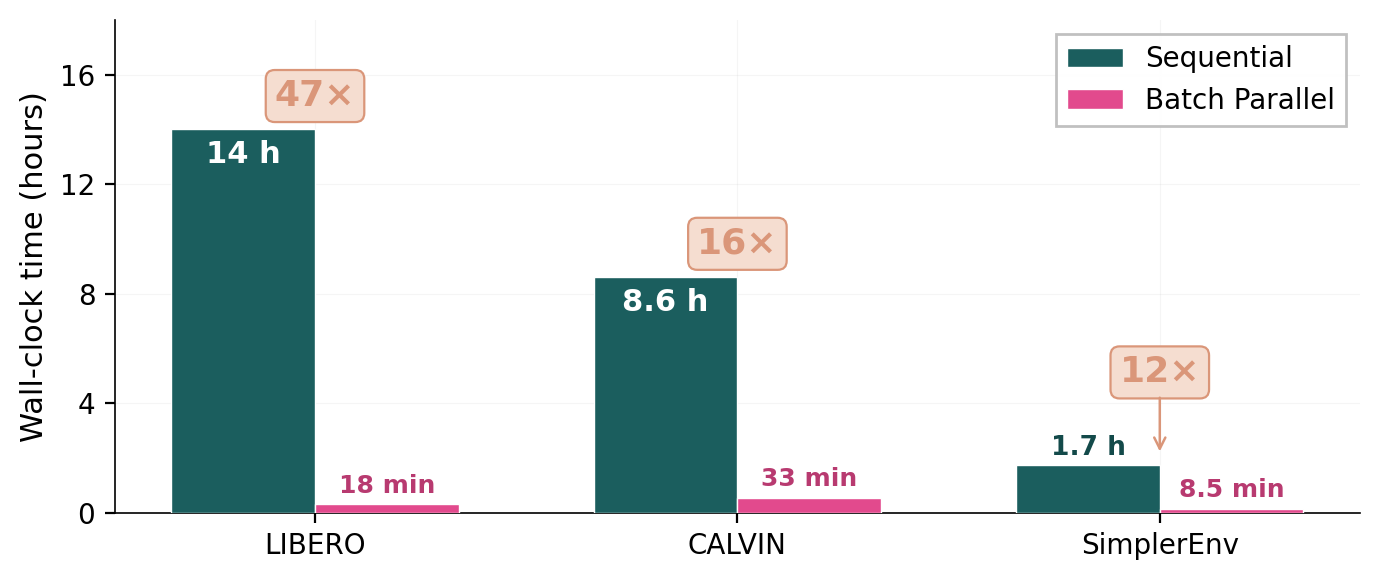
Recap — the modalities you already know
Week 10 deck · Multimodal LLM fusion patterns
| Modality | Canonical tokenizer | Example model |
|---|---|---|
| Text | BPE / SentencePiece | GPT, Llama |
| Image | ViT patches / VQ-VAE | CLIP, LLaVA, Chameleon |
| Audio | Mel-spec / EnCodec | Whisper, AudioLM |
| Video | Tubelets / latent frames | VideoMAE, Sora |
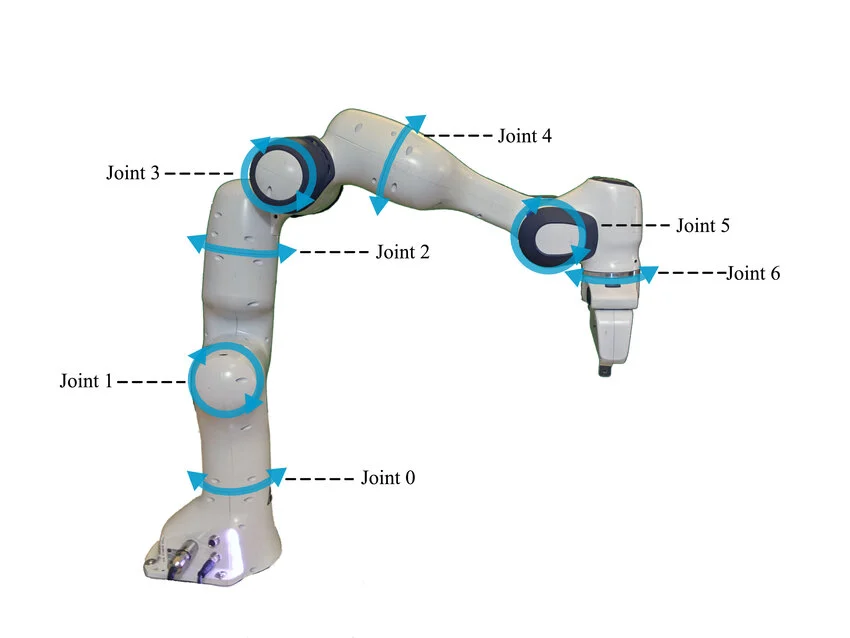
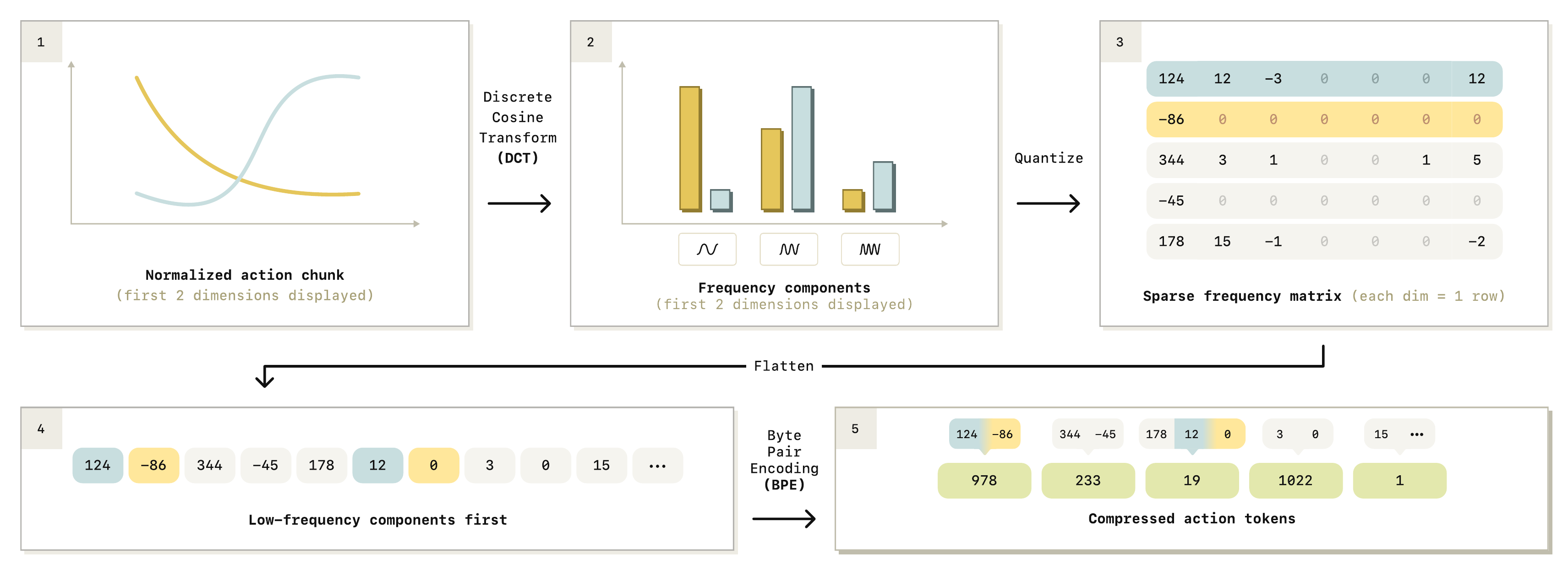
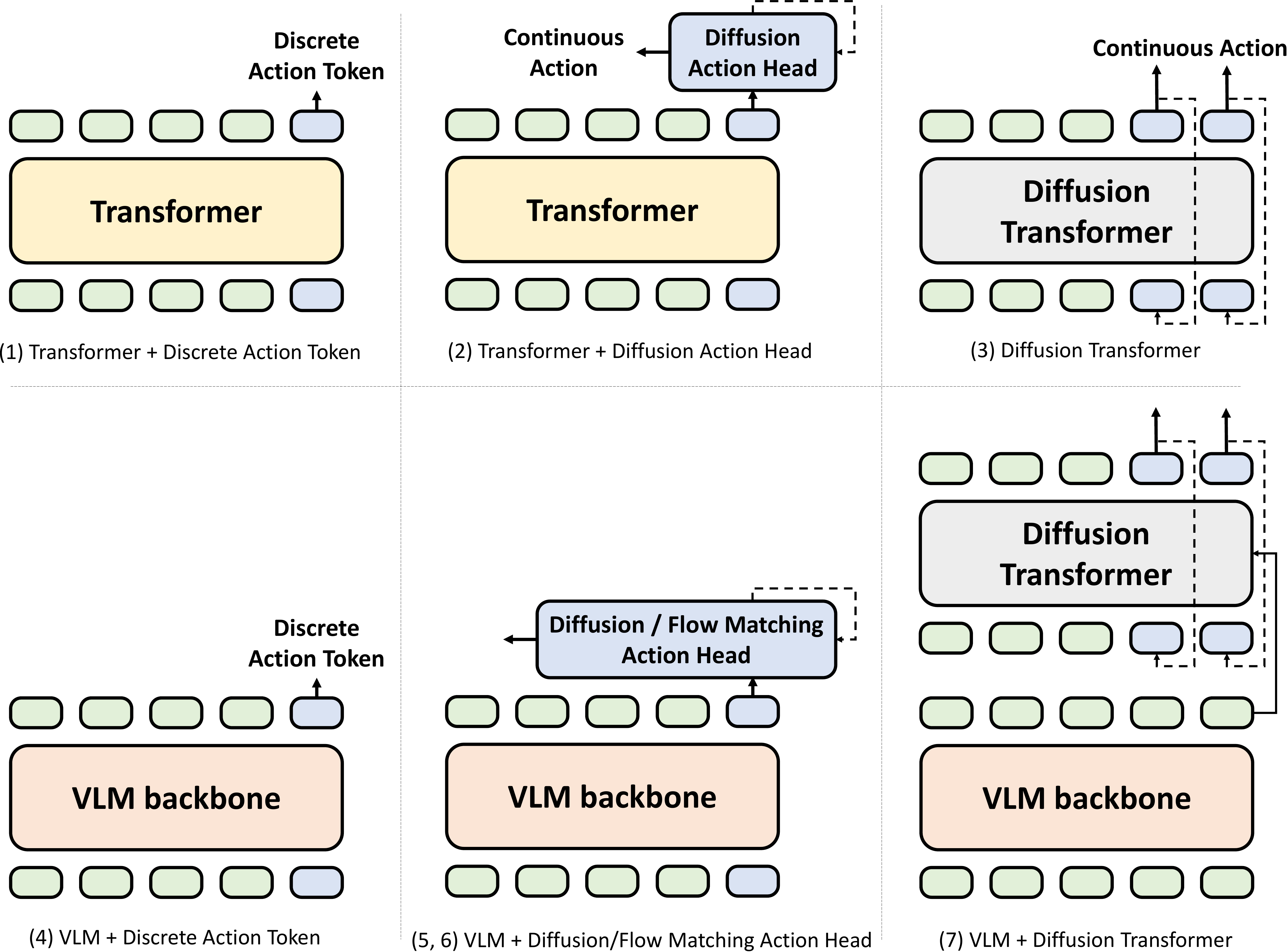
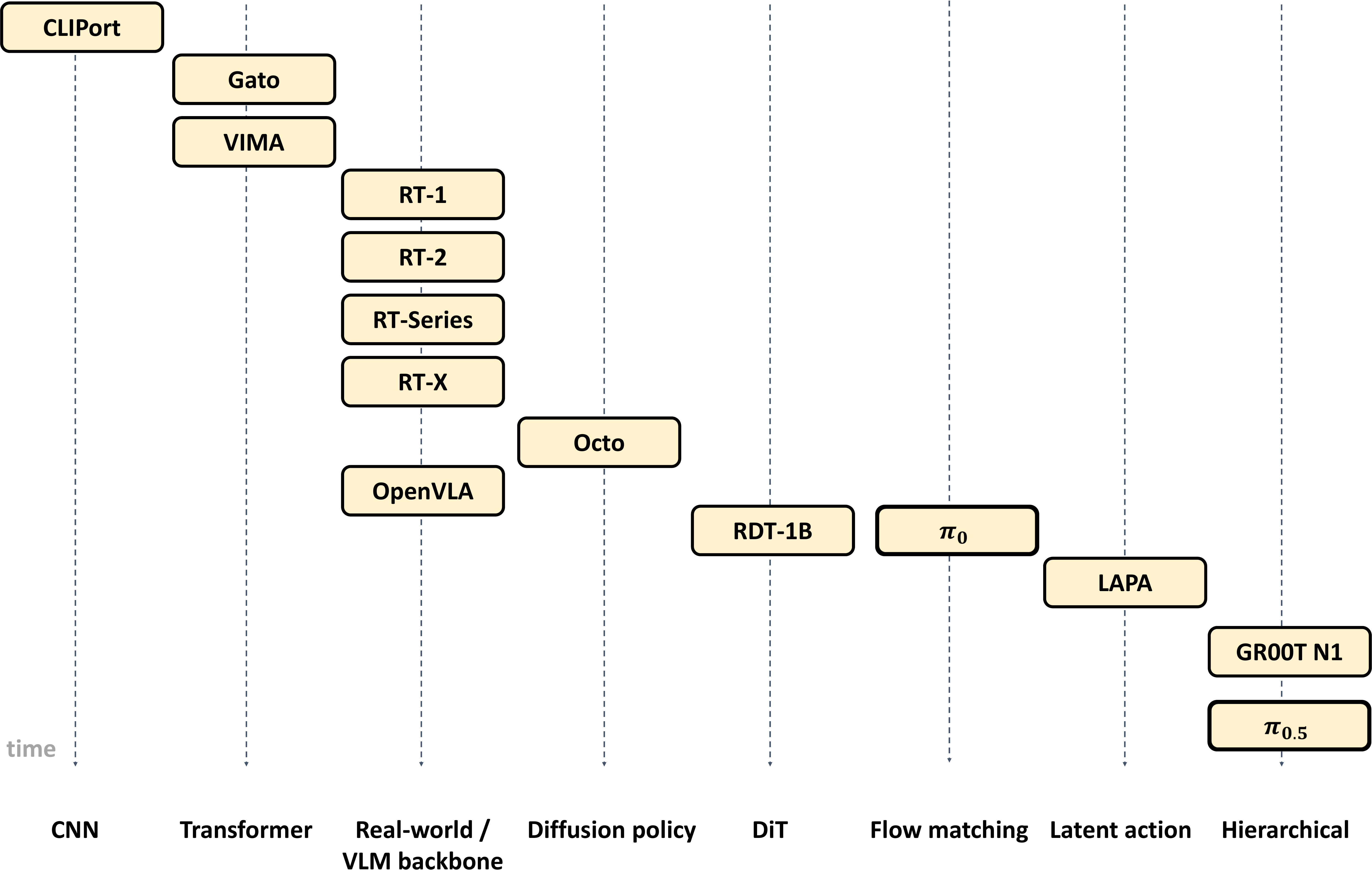
| ACTION | — today's question — | RT-1, π0, DreamZero |
We are adding one more row to a table the Week 10 deck already filled in.
Original figure · CLIP · Radford et al. 2021
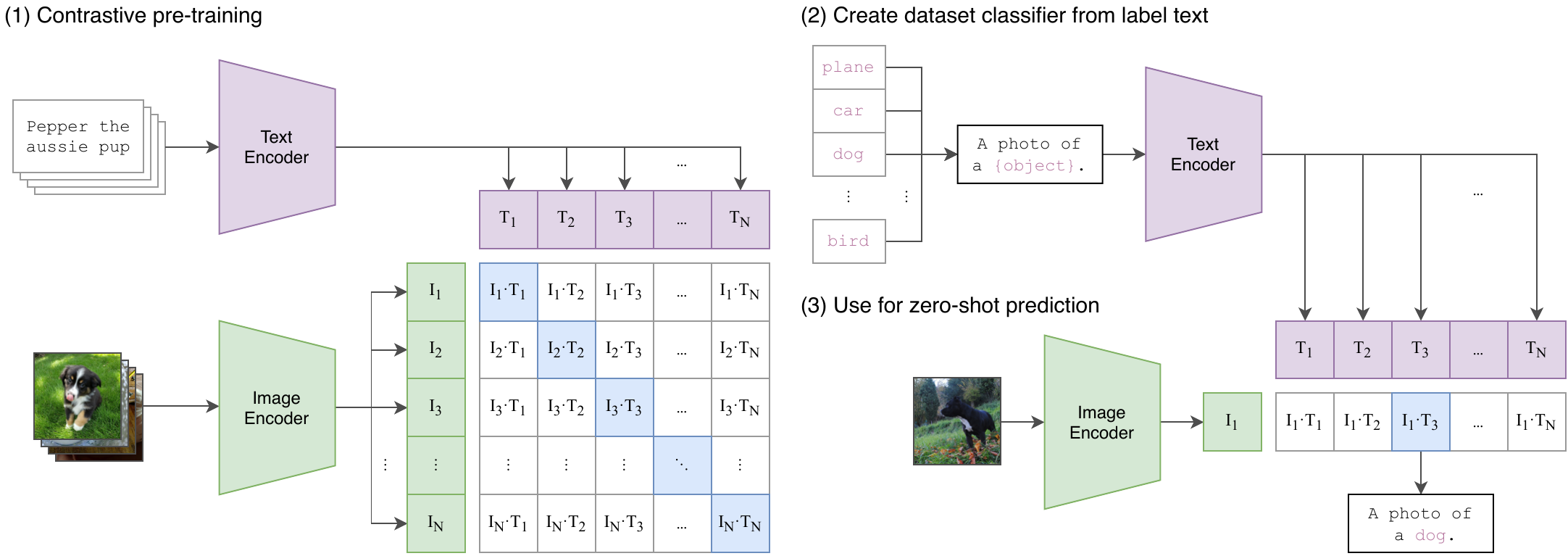
Image ↔ text tokens trained with contrastive loss — the canonical proof that any modality fits the "tokenize & predict" recipe.